
Содержание
Шел пятый час сбора заголовков и альтов… Мы проходили это сами. Помните панику, когда Google выпустил Panda, а все, кто копипастил контент, оказались в бане? Тогда мы учились писать уникальные тексты. Потом был Penguin — и мы освоили чистый линкбилдинг. Mobilegeddon заставил думать о мобильной верстке. Каждый раз, когда кто-то кричал «SEO умерло!», оно просто эволюционировало, требуя от нас новых навыков.
Сейчас эволюция ведет к автоматизации. XPath — один из путей. Пока одни тратят часы на рутину, другие одной строчкой запроса собирают данные для анализа, о котором раньше и мечтать не могли. Мы знаем, что эффективное SEO строится на данных, а не на догадках. И покажем, как XPath помогает эти данные добывать.
Суть проблемы
Типичная задача: нужно проверить alt-теги у 500 изображений в каталоге, собрать цены конкурентов с 50 сайтов или найти все внешние ссылки на вашем ресурсе. Стандартные парсеры и SEO-инструменты часто бессильны, когда нужны специфичные или динамические данные. Вам остается либо делать это вручную (и потратить неделю), либо просить разработчиков (и ждать месяц), либо сдаться.
Проблема в том, что современный SEO-специалист все чаще сталкивается с задачами, где нужно не просто собрать мета-теги, а достать конкретный кусочек информации из сложной структуры страницы. Именно здесь рутина побеждает интеллект, а время тратится впустую.
Как XPath в этом поможет?
XPath (XML Path Language) — это язык запросов для точной навигации по структуре HTML-документа (DOM) и выборки нужных узлов по заданным условиям.
Он описывает, как пройти по DOM-дереву от одного узла к другому. Путь состоит из шагов, разделенных символом /. Каждый шаг уточняет направление движения: по иерархии, через оси, предикаты и функции. XPath указывает, где именно находится нужный элемент на странице.
Узел в XPath — это не только HTML-элемент (<div>, <a>), но и:
- атрибут элемента (
href,alt,data-*), - текст внутри тега,
- комментарии и другие части документа.
С помощью XPath можно извлечь не просто ссылку как тег <a>, а, например, конкретное значение href, текст кнопки или описание изображения — то, что обычные парсеры часто не умеют делать без костылей.
Как это выглядит на примере:
//div[@class="product"]/h2
//— искать элемент в любом месте документа;div[@class="product"]— найти<div>с классомproduct;/h2— перейти к его прямому дочернему элементу<h2>.
По этому же принципу строятся и более сложные запросы — добавляются условия, фильтры и функции, которые позволяют выбирать данные максимально точно.
✌️ SEO без головомойки
Интересно? Подписывайтесь на наш телеграм-канал — там еще больше об инструментах, гипотезах и кейсах.
Как и где использовать XPath
Вам не нужно устанавливать сложные среды. Все начинается в браузере и решается в привычных инструментах.
1. Консоль разработчика
Откройте DevTools (F12), перейдите во вкладку Console. Введите команду:
$x("ваш_xpath_запрос"), например $x("//h1")
Так можно сразу проверить корректность XPath-выражения и сразу увидеть, какие элементы нашли на странице. Меняйте запрос, экспериментируйте, уточняйте условия, отлаживайте сложные конструкции, которые невозможно выгрузить с помощью стандартных инструментов — этот способ незаменим при работе с нетривиальными XPath.
2. Google Таблицы (IMPORTXML)
С помощью функции IMPORTXML и XPath можно извлекать практически любые данные из HTML-кода:
- Мета-теги (title, description, keywords).
- Заголовки различного уровня (H1-H6).
- Текстовое содержимое элементов страницы.
- Цены и характеристики товаров.
- Контактную информацию, включая email-адреса.
- Атрибуты ссылок и изображений.
- Структурированные данные и микроразметку.
Для регулярных выгрузок с нескольких URL прописывается формула:
=IMPORTXML("URL"; "XPath_запрос")
Вот готовые примеры для ваших задач:
| Что собрать | XPath-запрос | Как это работает |
|---|---|---|
| Все URL из sitemap.xml | //*[local-name()=’loc’]/text() | Извлекает содержимое тегов <loc>, игнорируя пространства имен. |
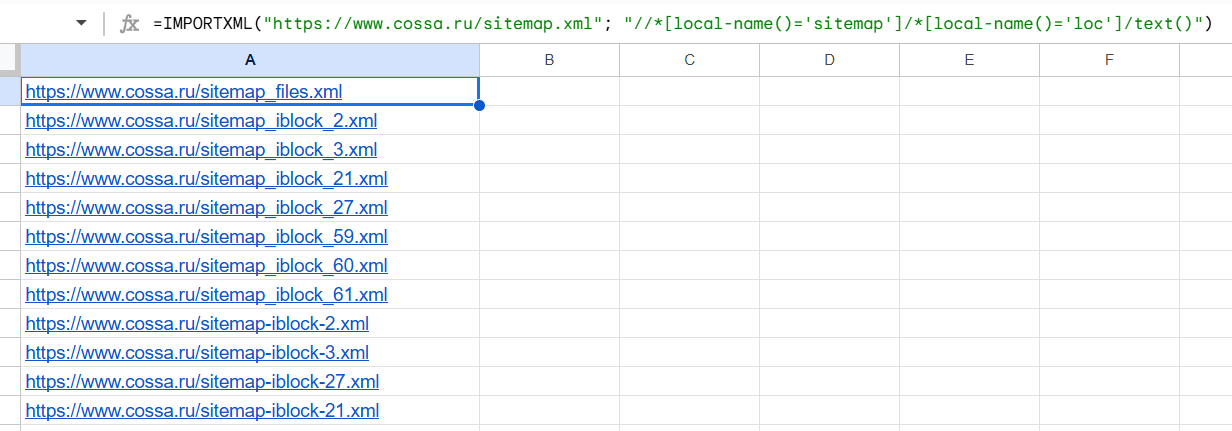
| Заголовок H1 со страницы | /h1/0 |
Несколько вариантов использования: • мониторинг собственных заголовков при массовых правках или миграции сайта; • сравнительный анализ заголовков на посадочных страницах у конкурентов; • выявление страниц без H1 или с дублирующимися заголовками; • контроль длины заголовков и их релевантности содержанию. |

| Цена со скидкой | //span[contains(@class, ‘price—discount’)] | Ищет <span>, в class которого есть подстрока price--discount. |
| Все email-адреса | //a[starts-with(@href,’mailto:’)]/@href | Находит ссылки, начинающиеся с mailto:, и берет значение атрибута href. |
| HTTP-код ответа сервера (через сервис bertal.ru) | =SUBSTITUTE(IMPORTXML(«https://bertal.ru/index.php?a9132898/BASH_URL»;»//div[@id=’otv’]/b»);»HTTP/1.1 «;»») | Сервис запрашивает URL и возвращает код, который формула очищает. |
А почему bertal?
- Bertal.ru — промежуточное звено, который выполняет HTTP-запрос к целевому URL и возвращает результат в структурированном виде.
- Формула возвращает числовой код ответа (200, 404, 500 и т.д.), который можно использовать для фильтрации и анализа.
- Для массовой проверки достаточно разместить список URL в столбце A и протянуть формулу.
Важно: IMPORTXML работает только с исходным HTML-кодом и не обрабатывает контент, подгружаемый через JavaScript.
3. Screaming Frog SEO Spider
Это самый мощный инструмент. В режиме Custom Extraction вы настраиваете правила, и паук собирает данные со всех страниц.
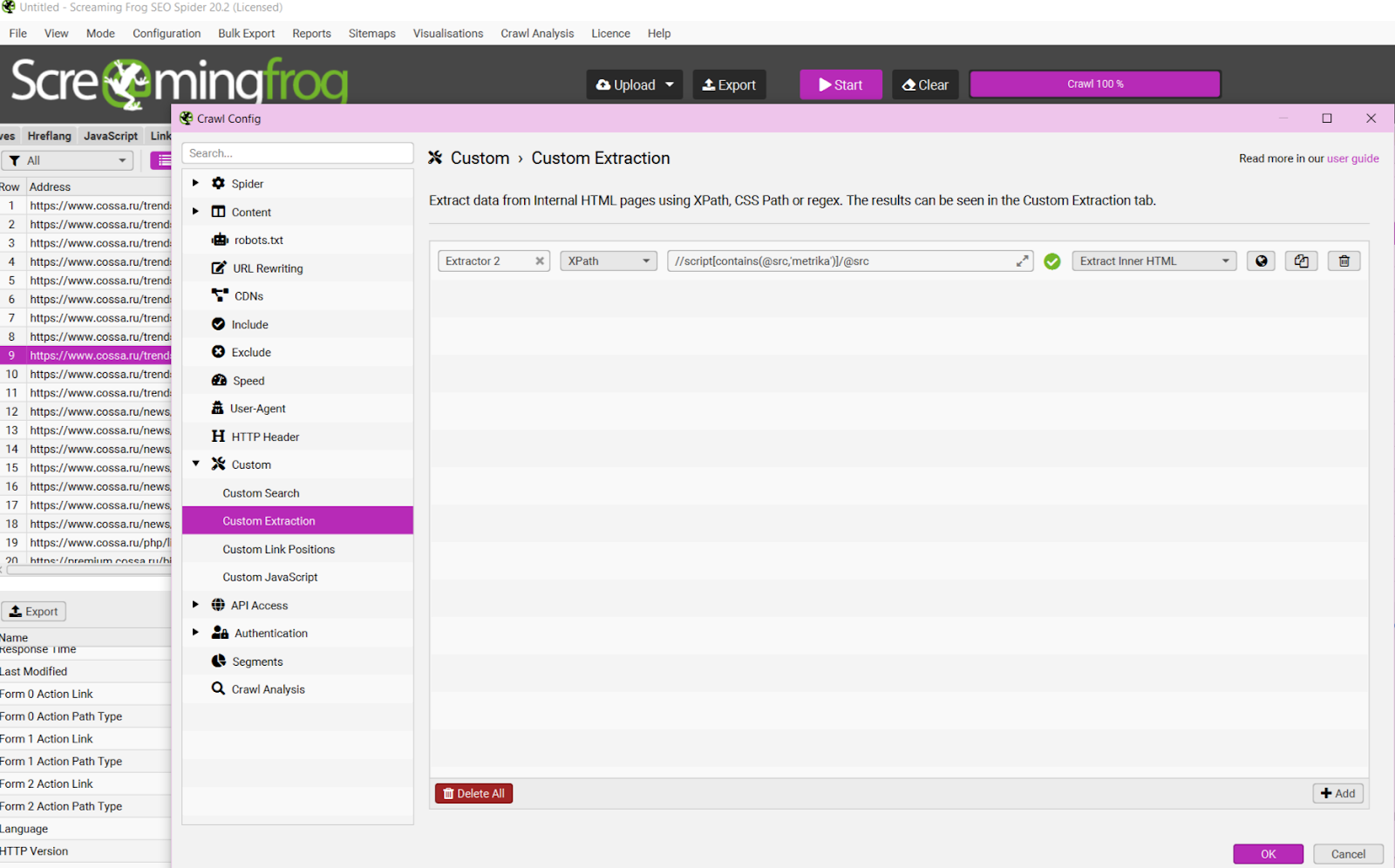
Алгоритм настройки извлечения данных:
- Запустите сканирование в режиме «Spider»
- Перейдите в раздел «Configuration» → «Custom» → «Extraction»
- Создайте новое правило, задав понятное имя
- Введите XPath-выражение для целевых данных
- Выберите тип извлекаемого контента (текст, атрибут)
- Запустите или перезапустите сканирование
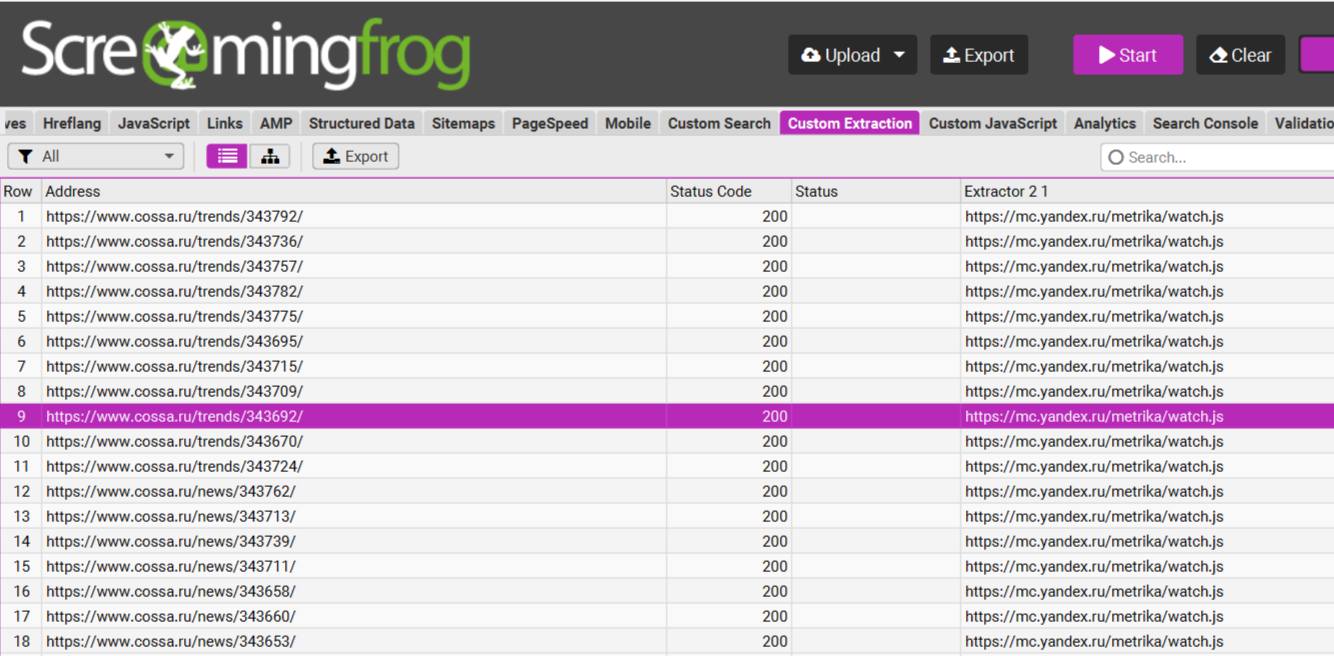
К примерам?
| Задача (что хотим проверить) | XPath-запрос | Зачем это нужно |
|---|---|---|
| Установлена ли Яндекс.Метрика? | //script[contains(@src,’mc.yandex.ru’)] | Массовая проверка корректности установки кода аналитики |
| Скрипты Google Tag Manager? | //script[contains(@src,’googletagmanager.com’)] | Аудит тегов и триггеров на всем сайте |
| Все внешние ссылки (без нашего домена) | //a[contains(@href,’http’) and not(contains(@href,’вашдомен.ru’))]/@href | Поиск нежелательных исходящих ссылок, анализ партнерских выходов |
| JSON-LD разметка | //script[@type=’application/ld+json’]/text() | Проверка наличия, валидности и полноты структурированных данных |
| Текст первого абзаца после каждого H2 | //h2/following-sibling::p[1] | Анализ качества вводных текстов в логических блоках |
| Наличие больших текстовых блоков | //div[string-length(text()) > 500] | Поиск страниц с достаточным для ранжирования текстовым контентом |
Пример из практики! Загружаете в паука список из 10 000 URL, добавляете правило для сбора email через //a[starts-with(@href,'mailto:')]/@href. Через час сканирования у вас готова чистая база контактов для линкбилдинга, которую вручную собирали бы неделями.
Больше полезных запросов.
//a[starts-with(@href,'tel:')]/@href— для телефонных номеров;//a[contains(@href,'facebook.com') or contains(@href,'twitter.com') or contains(@href,'linkedin.com')]/@href— для соцсетей.
4. Для сложных задач: Python
Когда нужно обойти защиту, обработать JavaScript или спарсить десятки тысяч страниц, на помощь приходит Python с библиотеками lxml, BeautifulSoup или Scrapy. Эти инструменты дают полный контроль над парсингом: можно работать через прокси, менять пользовательских агентов, обрабатывать JS-контент и выстраивать сложную логику обхода. Начать при этом можно с простых скриптов, например для автоматизации выгрузок из Google Таблиц.
А мне это точно надо? Краткий ответ — да
SEO становится интеллектуальнее. Роль специалиста смещается от простого сбора ключей к глубокому анализу данных и автоматизации. XPath — это как раз навык для этого перехода.
👌 База, которая нужна всем
Если хочется копнуть глубже — разбирать реальные кейсы, нетривиальные запросы и автоматизацию, — мы регулярно пишем об этом в блоге и канале.
Читайте дальше в нашем блоге: «Как попасть в Поиск с Алисой»
Почему XPath — это клево:
- Он экономит десятки часов рутинной работы.
- Вы получаете данные, недоступные в стандартных инструментах.
- Можно провести глубинный анализ конкурентов.
- Он помогает ставить точные задачи разработчикам («исправьте `alt` в элементах, которые находит вот этот запрос»).
Раз надо, так надо
XPath — это тот самый переход от ручного труда к автоматизированной аналитике. Это не «просто еще один инструмент», а фундаментальный навык, который меняет ваш рабочий процесс. Вы больше не пассивный сборщиком данных, который зависит от готовых отчетов, а активный добытчик.
Это способ упростить рутинные задачи в SEO и быстрее получать нужные данные. Не вместо мышления, а для того, чтобы тратить меньше времени на механику и больше на анализ и решения. Вместо ручных проверок и долгих выгрузок вы можете за несколько минут собрать заголовки, тексты, цены или контакты сразу по всему сайту. Это особенно полезно, когда страниц много, а времени нет.
Барьер входа низкий, а отдача огромная. Не пытайтесь выучить весь синтаксис за день. Учитесь решать конкретные задачи.
Читайте лучшие материалы первыми
Подписавшись на рассылку, вы соглашаетесь с Политикой Конфиденциальности.


