
Содержание
Самая частая ошибка в проектах на зарубежном рынке — переводить русские ключи. На практике это почти всегда уводит в сторону: регион, язык, привычки поиска и конкуренция меняют формулировки и даже смысл запросов. Поэтому под международный рынок семантику собирают заново. Семантическое ядро в этом смысле работает как карта спроса: по ней проще собрать структуру сайта, выбрать темы для контента и не потеряться в приоритетах на старте. В этой статье разберем, почему перевод ломает картину спроса и как выстроить сбор ядра так, чтобы оно отражало настоящую выдачу и поведение пользователей.
Это серия статей о сборе семантического ядра для российского и зарубежных рынков. О тонкостях работы с этой темой рассказывает SEO Senior WSS — Ксения Чайка. Ксюша ведет проекты с высокой конкуренцией и сложной структурой сайта, где ошибка в семантике быстро превращается в потерю трафика и конверсий.
👉 Первую часть о сборе семантики для российского рынка читайте здесь.
Отличие русскоязычной семантики от буржа
Разница между русскоязычной и зарубежной семантикой в SEO достаточно большая, и она касается сразу нескольких аспектов: поискового поведения пользователей, конкуренции и структуры запросов. Основные отличия:
| Отличие | Русскоязычная семантика | Зарубежная семантика |
|---|---|---|
| Региональная специфика | Один язык чаще рассматривают как один рынок | Один язык включает разные рынки: US, UK, CA, AU |
| Синонимы и вариативность | Вариантов формулировок обычно меньше | Вариантов и синонимов больше |
| Сленг и разговорные формы | Разговорные формулировки встречаются реже | Разговорные формулировки встречаются чаще |
| Длинные запросы | Длинные запросы чаще занимают меньшую долю спроса | Длинные запросы чаще занимают большую долю спроса |
| Выдача Google | Выдача чаще менее насыщенная | Выдача более насыщенная и конкурентная |

Шаг 1. Подготовка: ниша, тематика, конкуренты
Этот шаг задает основу для всего ядра. Если начать сбор без четкой рамки по нише, рынку и конкурентам, семантика быстро расползается: появляются запросы не по теме, не для нужной страны и с другим интентом. Когда база зафиксирована, дальше проще собирать ключи, группировать их и понимать, какие темы и страницы станут нужны сайту.
Изучите тематику сайта и услуги клиента
На первом этапе определяем:
- Чем занимается сайт.
- Какие продукты или услуги он предлагает.
- Какую проблему решает для пользователя.
- Географию и язык аудитории.
На этих ответах далее будет держаться и подбор запросов, и их группировка.
Анализ конкурентов и смежных ниш
Посмотрите, по каким запросам продвигаются прямые конкуренты: это быстро показывает, какие темы уже есть в выдаче и где придется конкурировать. Для сбора подойдут Ahrefs, Semrush, Serpstat и аналогичные инструменты.
Дальше полезно расширить угол: найти 2–3 смежные ниши, близкие по смыслу, но не совпадающие один в один. Они часто дают дополнительные формулировки и связки, которые не видны внутри вашей категории. Чем ближе смежная ниша к вашей, тем выше шанс получить идеи, которые реально можно применить.

Ищите идеи на форумах и тематических сайтах
Инструменты показывают частотность, но редко объясняют, как человек думает и какими словами он описывает свою задачу. Форумы и нишевые сообщества закрывают именно это: там виден живой язык аудитории и типовые формулировки, которые потом превращаются в запросы. Например, вводят ли они «дешевый продукт X» (cheap product X), «как выбрать сервис Y» (how to choose service Y) и т. д.
Как использовать форумы и тематические сайты:
- Определите популярные площадки в вашей нише. Для бурж-рынка это могут быть Reddit, Quora, нишевые форумы и сообщества.
- Анализируйте обсуждения. Обратите внимание на вопросы, темы и формулировки пользователей — именно так люди вводят запросы в Google.
- Собирайте «длинные хвосты». Часто на форумах встречаются точные и специфические фразы, которые практически не конкурируют в поиске, но приводят целевой трафик.
- Смотрите разделы «Похожие обсуждения» (Related discussions) или «Похожие темы» (Similar threads). Это помогает находить смежные темы и расширять перечень ключевых слов.
ИИ-агенты в более чем 40% случаев ссылаются на Reddit, что делает его источником трендовых и актуальных фраз.
Такие площадки помогают находить живые формулировки, которые в инструментах не всегда видны сразу. Поэтому такой подход дает новые углы темы и кластеры, которые можно забрать до того, как их займут конкуренты.
Используйте Википедию для расширения семантики
Википедия отличный инструмент для поиска идей ключевых слов и смежных тем, особенно для международных рынков. Ее структурированные статьи помогают выявить термины и концепции, которые реально ищут пользователи, а иногда — даже более точные, чем общие запросы в поисковиках.
Почему это полезно:
- Позволяет находить низкоконкурентные и тематически релевантные фразы.
- Расширяет семантическое ядро за счет смежных и редко упоминаемых тем.
- Помогает точнее формулировать ключи для целевой аудитории бурж-рынка, учитывая язык и привычки поиска.
Шаг 2. Сбор ключевых слов на английском и других языках
Во втором шаге закладывается набор запросов, который дальше будет чиститься, группироваться и раскладываться по страницам. На зарубежном рынке именно на этом этапе чаще всего всплывают расхождения языка и регионов, поэтому важно собрать варианты из нескольких источников и сразу сверяться с тем, что показывает Google. Если сбор сделан внимательно, дальше меньше ручных переделок и меньше риска строить структуру вокруг формулировок, которыми аудитория почти не пользуется.
Инструменты для сбора семантики
Вот ключевые инструменты, которые подойдут для англоязычного рынка:
- Google Keyword Planner. Базовый, бесплатный (или почти) инструмент от Google (недоступен из России).
- Google Trends. Бесплатный инструмент от Google для отслеживания трендов.
- Ahrefs, Semrush, Serpstat — платные, но дают больше данных по конкурентам, объемам, сложности.
Кстати, ИИ-боты (ChatGPT, DeepSeek и т.д.) подходят для первичного набора идей и расширения семантики, но полностью заменять ими ручную выборку нельзя. Модели часто ошибаются в нюансах языка, сленге и региональных различиях, из-за чего в выдачу попадают неестественные или «неживые» ключи.
Использование нескольких инструментов одновременно позволяет составить более полное семантическое ядро и минимизировать риск упустить важные ключи.
Подход к сбору семантики
Для зарубежного рынка важно учитывать не только сами слова, но и региональную специфику. Очевидный пример — различия в США, Великобритании и Канаде: один и тот же продукт или услуга может называться по-разному в разных странах:
| Значение | США (US) | Великобритания (UK) | Канада (CA)* |
|---|---|---|---|
| Квартира | Apartment | Flat | Apartment / Flat |
| Лифт | Elevator | Lift | Elevator / Lift |
| Грузовик | Truck | Lorry | Truck / Lorry |
| Печенье | Cookie | Biscuit | Cookie / Biscuit |
* В Канаде варианты зависят от провинции и контекста, иногда используют смесь американских и британских форм.
Для SEO это значит, что один и тот же ключевой запрос может иметь совсем разные варианты в разных регионах и разную частотность соответственно.
Важно знать, по какому конкретно региону продвижения сайт имеет первый приоритет и отталкиваться в первую очередь от региона, а не от языка.
Определите базовые ключевые слова
Начните с очевидных запросов: основные продукты, услуги или категории вашего сайта. Эти слова станут отправной точкой для расширения семантики. В первой итерации вы можете перевести ключевые слова через переводчик и посмотреть, насколько они релевантны выдаче — так вы сможете найти ряд конкурентов и составить их первичный список.
Изучите конкурентов
Посмотрите, по каким запросам ранжируются ваши прямые и косвенные конкуренты. Это помогает выявить востребованные ключи, которые вы могли упустить.
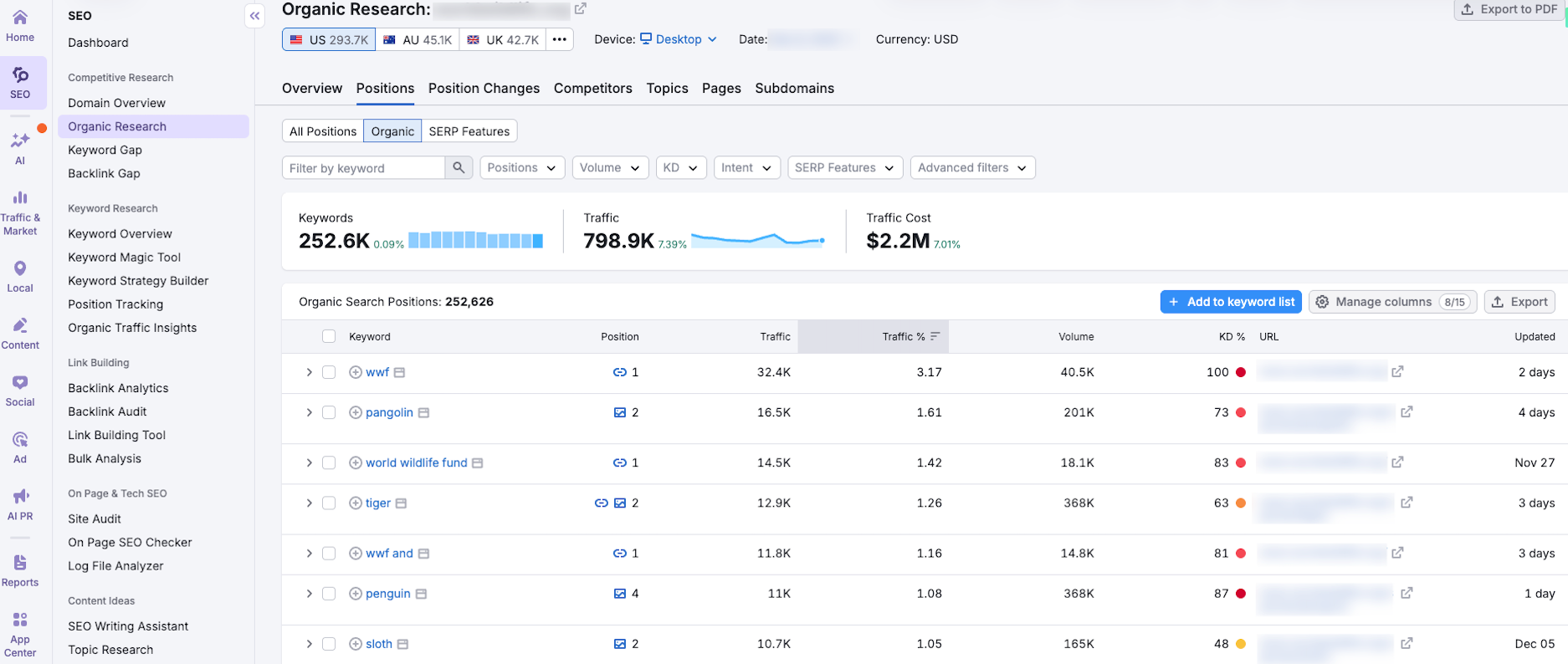
Проанализируйте трафиковые страницы конкурентов — это может быть источником идей для дополнительных посадочных страниц и семантики к ним.
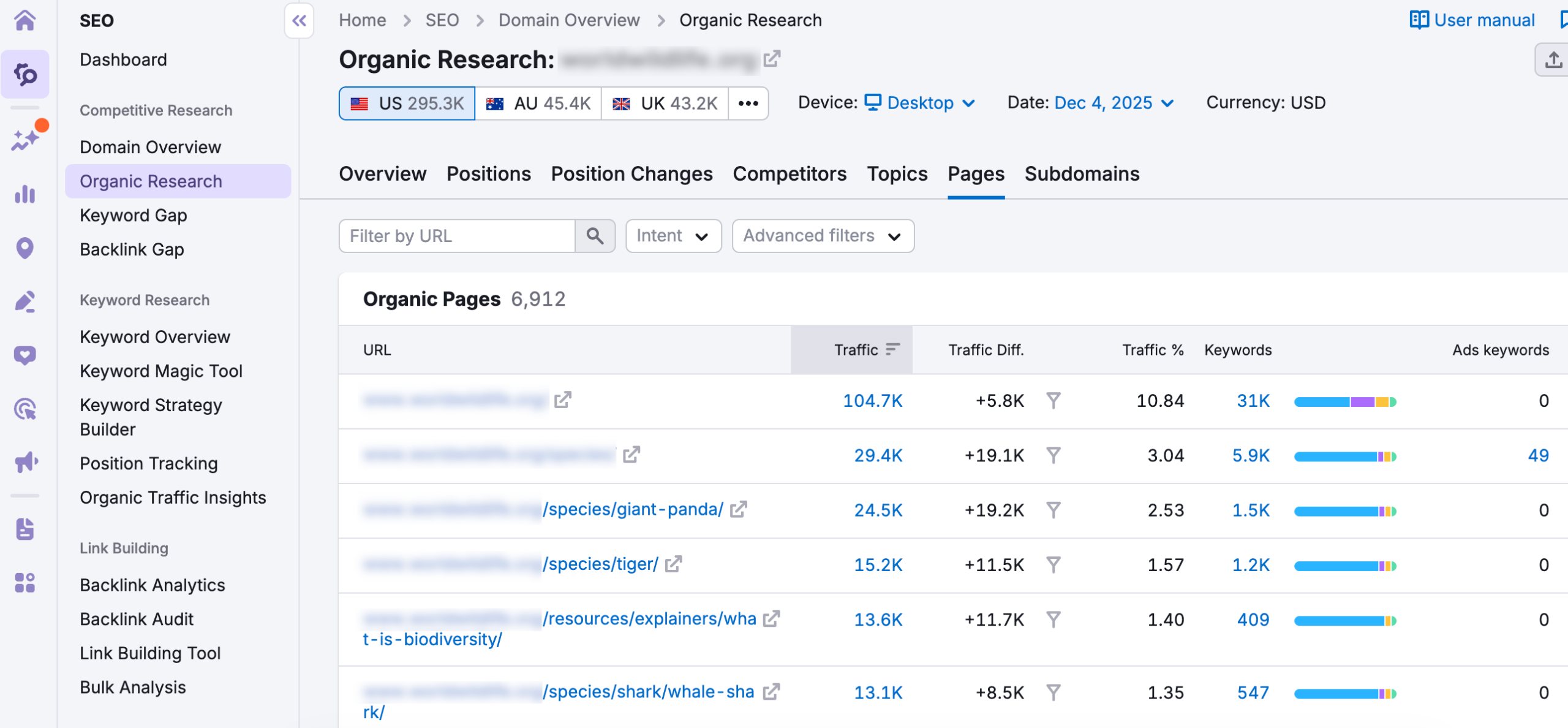
Расширяйте семантику
- Используйте синонимы и альтернативные формулировки.
- Добавляйте длиннохвостые ключи (long-tail) и вопросы, которые люди вводят в поисковике.
- Включайте смежные темы и фразы, найденные на форумах, Reddit, тематических сайтах и Википедии.
Учитывайте частотность запросов
Разделяйте ключевые слова по частоте:
- ВЧ (высокочастотные). Популярные, но высококонкурентные;
- СЧ (среднечастотные). Оптимальный баланс между трафиком и конкуренцией;
- НЧ (низкочастотные). Узкоцелевые, чаще с высокой конверсией.
Не ограничивайтесь только ВЧ- и СЧ- запросами: низкочастотные могут давать лучший конверсионный трафик.
Обращайте внимание на Keyword Difficulty
Keyword Difficulty (KD) — это показатель сложности продвижения запроса. В разных инструментах (Ahrefs, Semrush, Serpstat) он считается по-разному, но смысл один: чем выше KD, тем сильнее конкуренция и тем сложнее попасть в топ.
Например, запрос «лучший VPN для приватности» (best VPN for privacy) может иметь KD 70. Обычно это означает, что в выдаче закрепились крупные и авторитетные сайты, и одной обычной статьей такой запрос не взять.
Иногда за высокочастотным запросом с KD 70 гнаться невыгодно. Лучше выбрать запрос со средней частотой и KD около 30: по нему проще выйти в топ, и он чаще приводит более целевых пользователей, даже если общий трафик будет меньше.
Шаг 3. Очистка и кластеризация собранной семантики
После первоначального сбора вы получите большой список запросов — с дубликатами, нерелевантными словами, брендами, мусорными фразами.
Какие запросы стоит удалить
Глобально подход такой же, как и в русскоязычной семантике. Разница лишь в языковых нюансах, но принципы остаются универсальными. Удаляем:
- Брендовые запросы, если компания не работает с этими брендами.
- Запросы со словами «бесплатно» (free), «скачать» (download), «вики» (wiki), «работа» (job), «вакансия» (vacancy), «б/у» (used) — если они не соответствуют цели сайта (например, «б/у» (used) iPhone — если сайт продает только новые смартфоны).
- Городо- и странозависимые запросы, если они не имеют смысла для вашей географии.
- Дубли — например, «как сделать простой торт»(como fazer bolo simples) и «простой торт как сделать»(bolo simples como fazer).
Однако механическая очистка без проверки топов может привести к ошибкам. Даже после удаления дублей, брендовых и явно неподходящих запросов список может выглядеть аккуратно, но это не гарантирует, что запросы сгруппированы правильно. Формулировки, которые кажутся одинаковыми по смыслу, иногда ведут к разному интенту, и это видно только в выдаче.
Поэтому когда уже есть базовый очищенный список, следующим шагом становится проверка поисковой выдачи (SERP) по каждому ключу и определение, какие запросы должны относиться к одной группе. Если по двум формулировкам в топе ранжируются одни и те же страницы, то интент совпадает и такие запросы можно объединять:
- Пробейте каждый запрос в Google и посмотрите топ-10/20 результатов. Например, используйте инструмент Arsenkin.
- Сравните URL-адреса и типы страниц, которые ранжируются по разным запросам.
- Если одни и те же страницы появляются по нескольким разным ключам — это почти всегда означает, что:
- Эти запросы имеют один и тот же интент.
- Google считает их тематически близкими.
- Они должны лежать в одной группе / кластере.
Почему это важно:
- Это позволяет правильно структурировать сайт и избежать каннибализации ключевых слов.
- SERP-анализ показывает реальные намерения пользователей лучше, чем любые инструменты.
- Особенно полезно при работе с языками, которые вам незнакомы: вместо угадывания, что значит запрос, вы просто смотрите, какие страницы Google считает подходящими.
Даже если перевести иностранное словосочетание на русский, смысл и контекст могут не совпасть с тем, как его понимают носители. Из-за этого легко ошибиться в группировке: объединить запросы, которые относятся к разным темам и интентам, или наоборот, разделить то, что должно быть вместе.
Шаг 4: Составление структуры страниц под семантику
На этом этапе собранные и кластеризованные ключевые слова необходимо превратить в конкретную структуру сайта. Каждому кластеру назначается отдельная страница или раздел, что позволяет создавать контент, максимально релевантный поисковым запросам и логично организованный для пользователей.
Основные действия на этом шаге:
- Назначение ключей на страницы. Определите, какие ключи будут основными, а какие поддерживающими. Это помогает избежать каннибализации и дублирования контента.
- Планирование структуры. Продумайте иерархию страниц, учитывая важность кластеров и логику навигации. Главные кластеры часто становятся категориями, а второстепенные отдельными подстраницами или FAQ-блоками.
- Определение формата контента. Подумайте, какой тип страниц лучше раскрывает запрос: статья, гайд, сравнение, лендинг или FAQ.
- Оптимизация под интенты. Убедитесь, что каждая страница отвечает на конкретный интент пользователей, включая информационные, коммерческие и навигационные запросы.
Учитывайте тенденции современного SEO
Современные поисковые системы все меньше зависят от точных вхождений и все больше — от понимания смысла. Google активно ориентируется на сущности (entities), контекст, связи между понятиями и общую тематику страницы. Это значит, что при работе с семантикой важно учитывать не только ключевые фразы, но и то, какие объекты, события, характеристики и связанные темы должны быть раскрыты в материале.
👇 Подробный разбор о переходе индустрии к Entity SEO подготовил Team Lead WSS Виктор Прядильщиков в статье для Топвизора.
Читать
Что это меняет в процессе сбора семантики:
- Фокус на сущностях, а не на ключах-синонимах. Вместо того чтобы собирать десятки вариаций вроде «лучший VPN» (best VPN), «топ VPN-сервисов» (top VPNs), «VPN с лучшими оценками» (VPNs best rated), важнее определить основные сущности:
- VPN (виртуальная частная сеть).
- Encryption (шифрование).
- No-logs policy (политика отсутствия логов).
- Tunneling protocols (туннельные протоколы).
- Speed tests (тесты скорости).
Эти сущности и есть каркас, вокруг которого формируется контент.
- Google связывает фразы через смысл. Даже если пользователь вводит малоизвестный запрос, Google понимает, что он относится к определенной сущности. Поэтому семантически богатый текст, который раскрывает тему комплексно, часто ранжируется лучше, чем страницы с плотным набором ключей.
- Даже если эти слова не имеют высокой частоты, они помогают Google понять, что страница глубоко раскрывает тему.
- Снижается важность точных вхождений. В англоязычном сегменте много вариантов формулировок, и Google часто воспринимает их как один смысл:
- «Как начать блог» (how to start a blog).
- «Начать блог» (starting a blog).
- «Гайд, как начать блог» (blog start guide).
- «Ведение блога для новичков»(blogging for beginners).
Поэтому включать каждую вариацию в семантику перестало быть критически важным. Гораздо важнее — структура и смысловые блоки.
- Поддерживайте широкую тематическую сеть. Чем больше связанных сущностей вы охватываете — тем проще Google определить ваш сайт как экспертный. Это напрямую влияет на E-E-A-T и на долгосрочное ранжирование.

Типичные ошибки при сборе СЯ под бурж
Ошибки здесь, как правило, появляются в двух местах: когда путают язык с рынком и когда собирают список запросов без проверки выдачи. Ниже — основные промахи и короткие ориентиры, чтобы их избежать.
| Ошибка | Почему это проблема | Как избежать |
|---|---|---|
| Перевод русских ключей как основа семантики | Перевод не гарантирует, что так ищут на выбранном рынке и что интент совпадает | На старте допустим перевод как черновик для поиска конкурентов, дальше запросы подтверждать выдачей выбранной страны |
| Игнорирование поиска по разным странам и вариантам языка | Один язык дает разные формулировки и разную выдачу | Сразу фиксировать приоритетный рынок и собирать семантику по стране, а не по языку |
| Доверие ИИ без проверки SERP | ИИ предлагает варианты, но не подтверждает интент и тип страниц в топе | Использовать ИИ для идей, а группировку и приоритизацию делать после проверки топ-10/20 в Google |
| Механическое копирование синонимов | Список раздувается дублями или запросами с другим смыслом | При расширении оставлять варианты, которые дают отличающуюся выдачу или добавляют новый интент |
| Неправильная группировка ключевых слов | Получаются смешанные интенты или каннибализация страниц | Кластеризовать по выдаче: если в топе повторяются одни и те же страницы, запросы объединять |
| Недооценка длинных запросов или нерелевантный подбор | Теряется целевой спрос или появляются случайные формулировки | При расширении отдельно собирать длинные запросы и фильтровать их по релевантности продукту и рынку |
| Игнорирование Reddit и форумов | Выпадают живые формулировки и темы, которые не всегда видны в инструментах | На этапе подготовки и расширения использовать форумы, сообщества, Википедию как источники формулировок и смежных тем |
| Отсутствие ориентира на сущности | Семантика превращается в набор вариаций, сложнее строить структуру и контент | На этапе структуры фиксировать ключевые сущности и связанные понятия, а затем назначать кластеры на страницы |
Это можно сделать быстрее
Поможем собрать семантику под конкретную страну и язык: с проверкой выдачи, аккуратной группировкой по интенту и фокусом на сущностях. На выходе — ядро, которое можно сразу превращать в структуру сайта и контент-план.
Читайте лучшие материалы первыми
Подписавшись на рассылку, вы соглашаетесь с Политикой Конфиденциальности.


