Содержание
Как данные появились в сети?
В марте 2024 года на GitHub были случайно опубликованы внутренние документы из Google API Content Warehouse. В документах — описания алгоритмов и факторов ранжирования, использующихся в поисковой системе Google.
Позже эти документы нашел Эрфан Азими, глава компании EA Digital Eagle, и пришел к известному в мире SEO Рэнду Фишкину, который и предал утечку огласке.
Google нам врал?
Если коротко, да. Слив гугла показал, что многие публичные заявления не соответствуют действительности. Документы раскрывают множество факторов ранжирования, о которых компания умалчивала, и те, использование которых прямо отрицала. Посмотрим, что об этом говорит один из главных специалистов по поиску в компании Google Джон Мюллер.
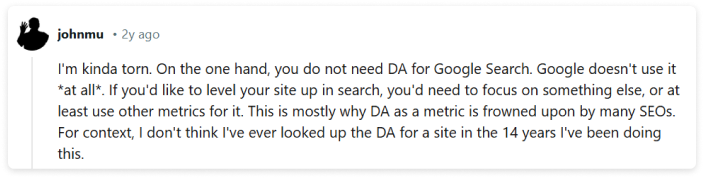
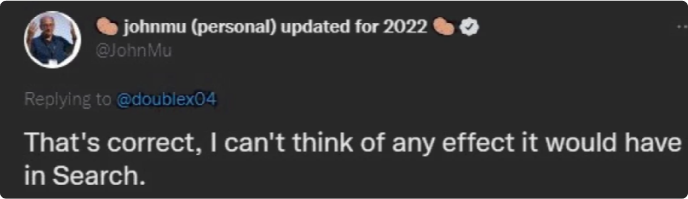
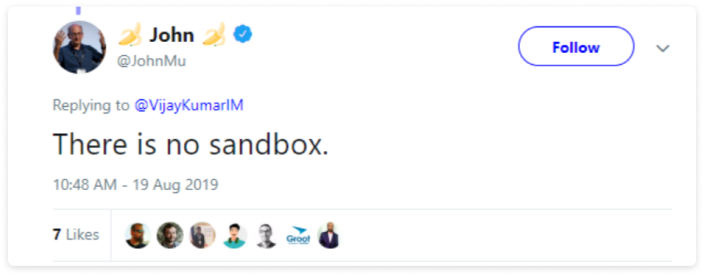
И это только малая часть того, что говорили представители Google. Теперь подробнее о том, как все работает на самом деле.
Авторитет сайта
Google утверждал, что не использует Domain Authority для ранжирования сайтов. Но в документах упоминается атрибут siteAuthority в модуле CompressedQualitySignals, который используется для оценки DA сайтов. Это подтверждает существование внутреннего алгоритма, учитывающего авторитет сайта в целом.
Поведенческие факторы в Google
Оказывается, Google следит и за кликами. Несмотря на то, что CTR или dwell time в доках не упоминаются, есть другая наводка.
Система NavBoost мониторит bad clicks, good clicks, longest clicks, unsquashed clicks и last longest clicks. Она рассматривает клики пользователей как голоса: сохраняет количество неудачных кликов и сегментирует данные по странам и устройствам. Основной показатель успешности — long clicks.
Песочница
Мюллер объяснял, что новым сайтам нужно больше времени на ранжирование, и это связано с естественным накоплением факторов (контент, бэклинки и вовлеченность), а не с преднамеренной задержкой от Google.
Все оказалось немного сложнее. Выяснилось, что Google использует механизм, который влияет на видимость новых сайтов, пока они не накопят достаточные доверие и авторитет. В документации к модулю PerDocData указан атрибут под названием hostAge, который используется «чтобы удержать новый спам [от появления в выдаче сразу после публикации]».
Влияние алгоритмов
Алгоритмы — ключевое звено в поддержании релевантности и качества поисковой выдачи. Два самых значимых, Пингвин и Панда, направлены на улучшение результатов поиска: они борются с низкокачественным контентом и манипулятивными ссылками. Но их влияние оказалось серьезнее, чем предполагалось.
Пингвин
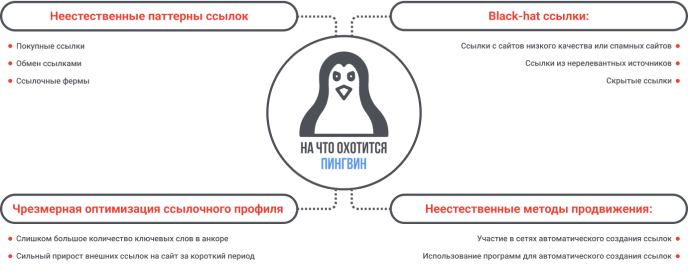
Утечка показывает, что Пингвин нацелен на поиск некачественных, спамовых и нерелевантных обратных ссылок. На ранжирование влияют только хорошие ссылки, а плохие понижают в выдаче.
Пингвин тщательно проверяет тексты на наличие неестественных шаблонов анкоров или чрезмерной оптимизации и наказывает сайты, которые используют черные методы линкбилдинга: дорвеи, прогон хрумером. Задача Penguin — быстро восстанавливать позиции сайтов, которые улучшают ссылочный профиль после санкций от поисковика, и штрафовать спамеров.
Обо всем этом мы уже давно знали, но спасибо гуглу за еще одно подтверждение. А что реально интересно в утечке, так это то, что во многих модулях фигурирует термин local, например droppedLocalAnchorCount. Получается, Google анализирует внутреннюю перелинковку и при подозрениях на переоптимизацию игнорирует такие ссылки.
Панда
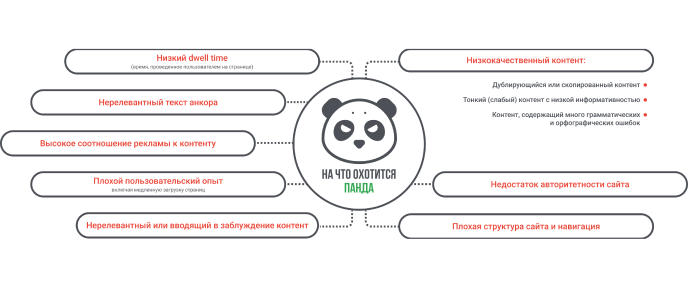
Уже давно есть фильтр, отслеживающий контент, — Google Panda. Детали работы фильтра не раскрывались, и Google отрицал учет поведенческих факторов на страницах.
Из слива мы узнали: алгоритм Панда охотится на низкокачественный или малополезный контент и понижает сайты с такими материалами в выдаче. Ранжирование сильно зависит от показателей поведения пользователей, например времени, которое они проводят на странице, и того, как они взаимодействуют с контентом. Высокий показатель отказов негативно влияет на рейтинг.
Важны не только качество и актуальность внешних ссылок. Понятно, что низкокачественные ссылки приводят к понижению. Нужно следить и за соответствием текста анкора ссылке: нерелевантные текст и ссылка плохо влияют на ранжирование.
Что еще мы узнали из слитой документации?
Даты публикации
При определении актуальности страниц система смотрит на дату публикации контента (bylineDate, syntacticDate). Google учитывает как дату публикации на странице, так и дату создания URL, чтобы точнее оценивать актуальность. За это отвечает атрибут TYPE_FRESHDOCS.
Траст главной страницы
Да, траст главной страницы важнее, чем мы думали. Слив подтверждает, что авторитет главной страницы сайта (siteFocusScore) влияет на ранжирование всех страниц сайта в Google, а общий авторитет домена — на его видимость в выдаче.
Ссылки
Чем более авторитетный сайт-донор, тем лучше будет ранжироваться ваш сайт. И чем ближе сайт по количеству ссылок к одному из таких доверенных сайтов, тем ценнее эти ссылки.
В документации это можно найти как атрибут PageRank-NearestSeeds (PagerankNs), заменивший классический PageRank. Это означает, что ссылки, полученные с авторитетных сайтов, имеют высокую ценность.
Первоисточники информации
Оригинальную информацию, которая была опубликована на гитхабе, можно посмотреть по ссылке. А подробнее о том, что это значит для специалистов, можно почитать у Рэнда Фишкина на сайте SparkToro.
Что делать SEO специалисту?
Возможно, стоит пересмотреть некоторые стратегии с учетом новых данных об алгоритмах Google. Очевидно, что поисковик уделяет особое внимание качеству контента и авторитетности. Работу с ссылками тоже нужно оптимизировать: обращать более пристальное внимание на релевантность и качество источников. Да — хорошим ссылкам, нет — плохим.
И, конечно, поменять подход к работе с поведенческими факторами. Да, удобная навигация, быстрая загрузка страниц и адаптивный дизайн — старая и понятная история. Но пользовательский опыт и ПФ для гугла важнее, чем мы думали.
DO’S
- Использование максимального количества релевантных сущностей внутри темы страницы (с учётом NLP)
- Добавление уникальной составляющей к тому, что уже и без вас есть в Интернете
- Учитывать 20 последних изменений для URL-адреса
- Свежий контент (поэтому ссылки из СМИ априори считаются качественными)
- Прокачивание общего траста сайта
DON’T’S
- Неоптимизированная мета (особенно title)
- Black hat SEO
- Плохое юзабилити
- Низкокачественный контент
- Верить официальным представителям поисковиков, когда те рассказывают что-то про алгоритмы ранжирования
Выводы
1. Слив алгоритмов Google подтвердил многие подозрения и теории. Утечке мы, конечно, рады, но не от всей души. С тех пор как теории стали реальностью, многие стратегии придется перестраивать и учиться работать в новых условиях.
2. Самое важное для гугла:
- Качество > количество. Лучше закупить меньше качественных ссылок, чем много средних или низкокачественных (помним про Пингвина).
- Качество контента — в приоритете.
- Авторитетность всему голова.
3. Большим корпорациям не стоит доверять. Удивительно, правда?
Читайте лучшие материалы первыми
Подписавшись на рассылку, вы соглашаетесь с Политикой Конфиденциальности.