
Содержание
Все больше людей ищут информацию не через Google, а напрямую у AI-ассистентов — ChatGPT, Gemini, Perplexity и других. Каждый из них по-своему работает с контентом, но основная цель у всех: быстро сгенерировать ответ на запрос пользователя. При этом часть таких ответов формируется на основе внешних источников — сайтов, к которым у модели есть доступ.
Для редакторов, SEO-специалистов и владельцев сайтов это означает одно: благодаря AI появляется новая поисковая выдача, в которую можно (и нужно) пытаться попасть. Но у чат-ботов другие алгоритмы: они не ранжируют сайты в списке, а формируют ответы. И работают не так, как Google или Яндекс.
В этой статье разбираемся, как нейросети обрабатывают контент, по каким принципам используют его в ответах и как получить от ИИ трафик.
Как AI-ассистенты ищут информацию
В этой статье под AI-ассистентами мы имеем в виду сервисы, которые принимают запрос в свободной форме и сами формируют связный ответ. Это не просто чат-боты, которые работают по скриптам, и не поисковики с привычным списком ссылок.
К таким ассистентам относятся ChatGPT, Gemini, Perplexity и Bing Chat — интерфейсы на базе нейросетей, которые работают по принципу генерации ответа, а не ранжирования.
Мы используем именно этот термин, потому что он точнее всего отражает суть: AI, который помогает найти и обработать информацию, но делает это иначе, чем Google или Яндекс.
AI-ассистенты не показывают список ссылок — они сразу формируют ответ. Это главное отличие от классических поисковиков, где пользователь сам выбирает, на какой сайт перейти.
В основе большинства современных AI-ассистентов — подход Retrieval-Augmented Generation, или сокращенно RAG. Он работает в два этапа: сначала модель находит релевантные документы, потом использует их как контекст для генерации ответа. При этом финальный текст пишет сама модель, и в нем может не быть ни одной прямой цитаты.
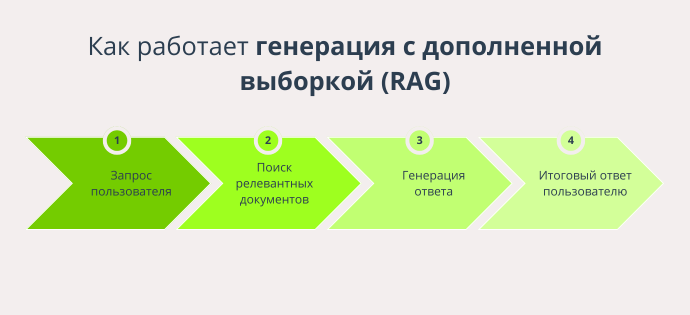
Для пользователя это удобно: он получает цельный и связный ответ, не переходя по ссылкам. Но для владельцев сайтов это создает новую задачу: чтобы контент попал в поле зрения AI, он должен сначала пройти отбор на этапе retrieval, а потом еще «понравиться» модели настолько, чтобы быть использованным в ответе.
Допустим, пользователь спрашивает у ChatGPT: «Можно ли замораживать творог?»
Что делает ChatGPT:
- На этапе retrieval. Ищет документы, где встречаются фразы вроде «заморозка творога», «можно ли замораживать», «условия хранения творога». Это могут быть статьи, инструкции, форумы, рецепты.
- На этапе generation. На основе найденных материалов нейросеть пишет свой ответ. При этом она не вставляет фрагменты текста, а формулирует мысль сама: «Да, творог можно замораживать, но после разморозки он может изменить текстуру и стать более рассыпчатым. Лучше всего использовать его для запеканок или выпечки».
Google на месте AI показал бы список ссылок на форумы, рецепты и статьи, чтобы пользователь сам выбрал, на что кликнуть.
Поисковая система vs AI-ассистент: как формируется выдача
| Классический поиск (Google, Яндекс) | AI-ассистенты (ChatGPT, Gemini, Perplexity) | |
|---|---|---|
| Результат | Список страниц по релевантности | Один ответ, сгенерированный моделью |
| Форма подачи | Заголовки, сниппеты, URL | Связный текст от первого лица |
| Источник информации | Индексация в реальном времени | База данных (статичная или обновляемая) + поиск по ней |
| Механика выбора | Ранжирование по алгоритму (PageRank, BERT, MUM и т.д.) | Retrieval + генерация (RAG, Synthesis) |
| Наличие ссылок | Обязательно | Иногда (Perplexity, Bing), чаще — нет |
| Роль SEO | Ключевые слова, структура страницы, внешние ссылки | Структура, четкость формулировок, репутация источника |
| Влияние пользовательского поведения | Высокое: поведенческие сигналы, CTR, время на сайте | Минимальное или отсутствует |
| Периодичность обновления | Постоянно | Зависит от модели: от статичной базы до краулинга «на лету» |
| Контроль над видимостью | Относительно высокий (через оптимизацию, вебмастер) | Частично возможен, но гораздо менее предсказуем |
Почему AI-ассистенты не ссылаются на сайты
В классической поисковой выдаче ссылки — основной результат. Пользователь сам выбирает, на что перейти. В случае с AI-ассистентами логика другая: ссылка — это необязательный атрибут.
Есть несколько причин, почему ссылки могут отсутствовать:
Ответ сформирован на основе обучающей выборки. ChatGPT без включенного Browse-модуля использует только ту информацию, которая попала в модель при обучении. У таких версий нет доступа к интернету, и они просто не знают, откуда именно взяли данные.
Ответ получен через генерацию, а не цитирование. Даже если ассистент получил доступ к реальным источникам, он не обязан использовать прямую цитату или ссылку. Задача модели — составить связный и информативный текст, а не оформить источники как в научной статье.
Упрощение интерфейса. Некоторые ассистенты намеренно убирают ссылки, чтобы не усложнять пользовательский опыт. Например, Gemini часто выдает короткий ответ без указания, откуда взята информация.
Работа через API и агрегированные базы. В ряде случаев ассистенты используют внешние базы знаний, например лицензированные в рамках партнерства, и тогда источник вообще не находится в открытом доступе.

Даже если AI-ассистент получил информацию из открытых источников, он может не отобразить их в ответе, особенно при простых запросах. Например, если попросить описать симптомы дефицита витамина D, ChatGPT просто перечислит основные признаки без указания, где он это прочитал.
Иногда источники можно запросить вручную. При вопросах вроде «Можешь дать ссылку на это?» или «Откуда эта информация?» — некоторые ассистенты (например ChatGPT с Browse или Bing Chat) попытаются сослаться на сайт. Но и здесь результат зависит от конкретной реализации.
ChatGPT с включенным Browse-модулем может перейти на сайт в момент запроса и встроить ссылку в ответ. Но даже в этом случае модель не всегда явно показывает, откуда взята конкретная формулировка. Иногда она ссылается на ресурс, который был найден в процессе, но фактически не использовался. Это связано с тем, что модель сначала формулирует ответ, а ссылки «приклеиваются» к нему в конце — как оформление, а не источник цитаты.
Perplexity работает как поисковик с RAG: сначала находит релевантные источники, затем формирует ответ с гиперссылками. Ссылки видны сразу и достаточно прозрачны, но могут вести на один и тот же сайт даже при разных формулировках. Они указывают скорее на общую тематику, чем на конкретную цитату — это особенность архитектуры генерации.
Bing Chat указывает ссылки прямо в тексте, с пронумерованными сносками. В «точном» режиме ссылки, как правило, соответствуют фактам, но в креативном и сбалансированном могут быть менее надежны. Причина та же: ответ создает генеративная модель, а ссылки добавляются поверх.
Gemini (Google) может указывать источники, особенно в интеграции с SGE (Search Generative Experience), но делает это выборочно. В основном работает без явных гиперссылок и чаще всего просто дает текст, без указания, откуда что взято.
Когда ссылки все-таки появляются
AI-ассистенты по-разному работают с запросами. Чем сложнее или специфичнее формулировка, тем выше шанс, что модель обратится к внешним источникам. Особенно если запрос связан с цифрами, новостями или сравнительным анализом.
Например, вопрос: «Какие технологии используют разные поисковики для генерации ответов?» — скорее всего, заставит ассистента обратиться к статьям или документации. То же самое касается сравнений, обзоров, упоминаний брендов или требований к программам — в таких случаях ассистенты чаще поднимают источники и могут добавить ссылку.
Если пользователь уточняет: «А можешь сравнить подход Google и Perplexity?» или «Какие у этого метода плюсы и минусы?» — модель стремится подтвердить ответ конкретными примерами. Особенно это заметно в Perplexity и Bing: они явно оформляют ссылки как часть логики ответа, а не просто как дополнение.
Чем менее общий вопрос, тем выше шанс, что появится источник. Особенно если ответ нельзя сформировать из «общих знаний» и требуется хоть какое-то документальное основание.
Как AI-ассистенты находят сайты
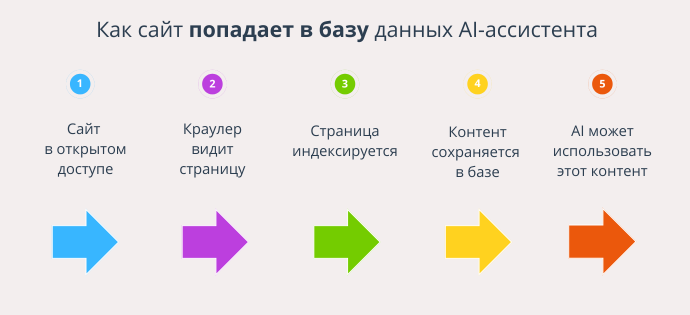
AI-ассистенты не сканируют интернет в реальном времени при каждом запросе. У них есть собственные базы данных, на которые они опираются при генерации ответов. У кого-то это статичная база, у кого-то — смесь обученной памяти и поискового механизма, а у некоторых — краулинг в момент запроса.
Чтобы сайт попал в ответ, он сначала должен попасть в эти базы. И здесь важна не только техническая открытость, но и то, с какими источниками работает конкретный ассистент.
База знаний AI-ассистента — это не копия всего интернета. У каждой модели — свой набор источников и подход к их обновлению. Например, ChatGPT в стандартной версии обучен на выборке из Common Crawl, Wikipedia, технической документации и других общедоступных данных. Perplexity и Bing Chat используют краулинг: могут обращаться к сайтам в момент запроса или регулярно обновлять собственную индексацию. Gemini комбинирует оба подхода: часть информации берется из модели, часть — из поискового индекса Google.
При этом важно учитывать, что ассистенты по-разному работают с актуальными данными из интернета. Например, ChatGPT с Browse в первую очередь опирается на индекс Bing. Многие генеративные поисковые сервисы (включая Perplexity и Phind) также используют Bing как один из ключевых источников веб-данных. Поэтому, даже если для вашей аудитории привычнее работать с Google или Яндексом, стоит уделить внимание тому, как ваш сайт виден именно для Bing.

Но чтобы ассистент смог прочитать страницу, она должна быть технически доступна. Это значит, что:
- она не запрещена для обхода в
robots.txt, - не помечена как
noindex, - не требует авторизации или не блокирует краулеров — программы, которые автоматически просматривают страницы сайта, переходят по ссылкам, считывают содержание и сохраняют его для дальнейшей обработки.
Ассистенты — не боты Google: если видят запрет, просто проходят мимо. Даже крупные и важные сайты не попадут в корпус, если формально были закрыты от обхода.
В некоторых случаях сайт может быть недоступен не из-за запрета, а из-за нестандартной разметки, медленной загрузки или ошибок в технической структуре. Но чаще всего причина в том, что модель просто не увидела сигнал: краулер не зашел, страница не попала в выборку, или контент был размещен в зоне, которая не попадает в обучающие датасеты.
При этом важно понимать, что привычные методы SEO здесь работают не полностью. В классическом поиске вы можете отслеживать индексацию страниц, позиции, переходы — и корректировать стратегию. С AI-ассистентами все иначе: у них нет списка выдачи, нет позиций и нет обратной связи. Даже если сайт попал в обучающую выборку или был просканирован краулером, это еще не значит, что его контент будет использован в ответе. Ассистент сам решает, что взять, как переформулировать и нужен ли источник вообще.
Что стоит учитывать при создании контента для AI-ассистентов
Особых требований к структуре текста со стороны AI-ассистентов нет. Они ориентируются на те же признаки, что и поисковые системы: понятная разметка, четкая логика, цельные фрагменты, списки и заголовки. Все, что давно работает в SEO и UX, продолжает работать — просто теперь это нужно не только для ранжирования в поиске, но и для того, чтобы ассистенту было проще встроить ваш текст в ответ.
Пока не существует инструментов, которые бы точно показывали, как и почему именно ваш контент оказался в выдаче ChatGPT или Perplexity. Громких кейсов тоже нет — и в зарубежном, и в российском SEO-сообществе все еще идет стадия наблюдения. Но некоторые закономерности уже обозначились.
AI-ассистенты, в том числе самый популярный среди пользователей ChatGPT, собирают ответ на основе того, что в среднем пишут источники по теме. Они не копируют текст с одного сайта, даже если он в топе — модели ищут повторяющиеся, устойчивые формулировки. Поэтому короткий, ясный, логически цельный фрагмент с понятной структурой может попасть в ответ.
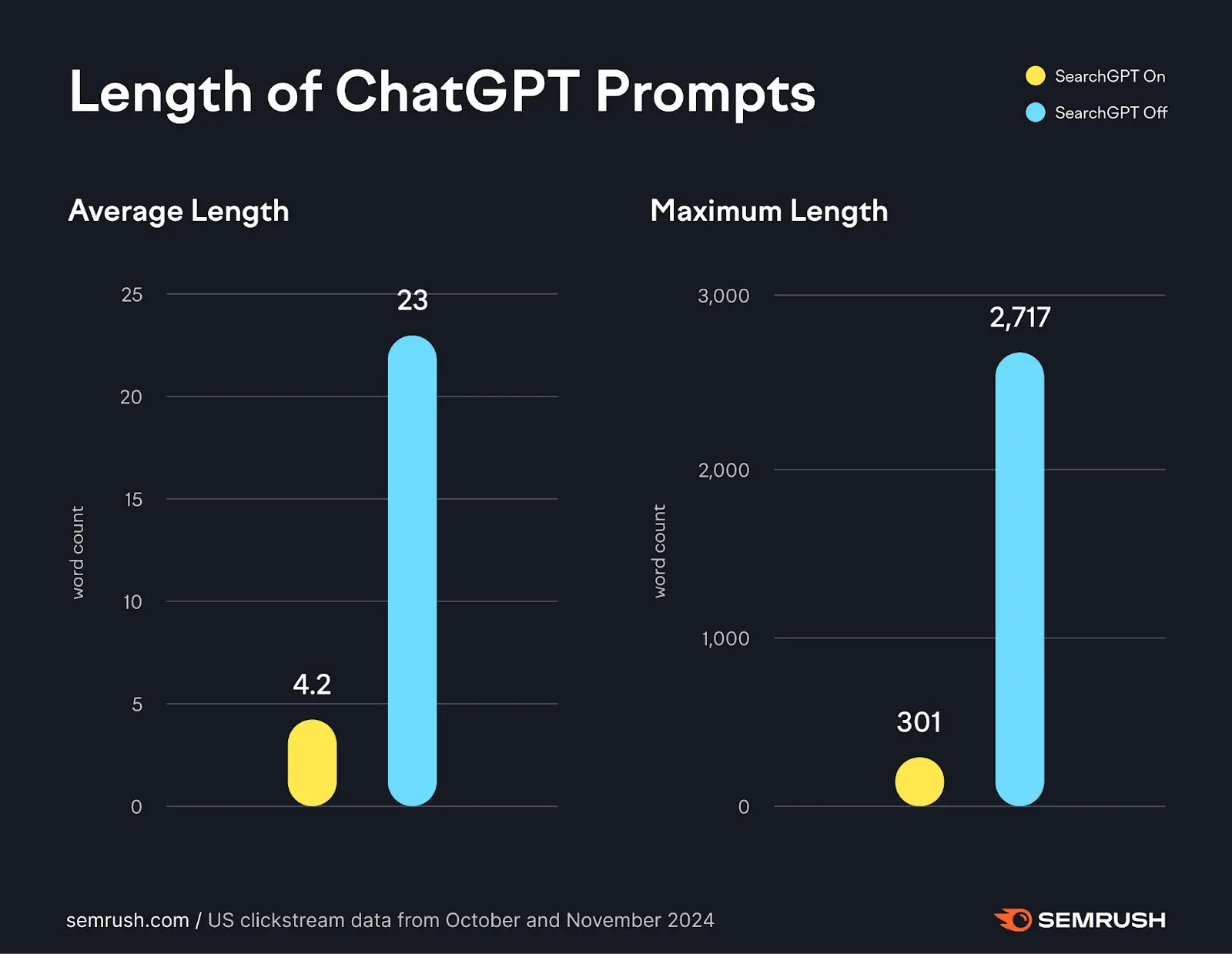
Исследование SEMrush показывает: запросы в ChatGPT длиннее и разговорнее, чем в поиске. Пользователи чаще просят объяснить, уточнить, посоветовать. В ответ они не кликают, а читают, и это меняет правила. Страница должна не направить к решению, а быть решением сама.
Добавьте к этому другой характер запроса: не фактологический, а прикладной, не «сколько стоит», а «как выбрать». В таких условиях хорошо работает контент, в котором есть:
- разные формулировки одного и того же ответа (включая разговорные);
- редкие и нетипичные вопросы, на которые все еще есть внятный ответ;
- фактура — примеры, вариации, детали, которые помогут модели сгенерировать что-то полезное.
Модели не ищут страницу. Они ищут кусок текста, который звучит как готовый фрагмент ответа. Все, что помогает этому фрагменту быть ясным и законченным, полезно и принимается.
Где сейчас реально получить трафик от нейросетей
Пока большинство AI-ассистентов (в том числе ChatGPT и Gemini) не гарантируют переходов на сайт, уже появились точки входа, где нейросети действительно приводят трафик. Это не совсем SEO в привычном смысле, но логика схожая: контент должен быть видимым, понятным, полезным — и находиться там, где его могут «поднять» генеративные движки.
Вот где сейчас можно получить трафик от нейросетей:
- AI-обогащенная выдача в поисковиках.
- Ассистенты с открытым браузером.
- Платформы с интеграцией ИИ.
Эти площадки работают по разным принципам, но у них есть общее: они стараются не придумывать, а обобщать уже опубликованное. Поэтому если ваш сайт — часть информационного поля, он может туда попасть.
Один из самых понятных источников — AI Overviews от Google. Это блок, который появляется над обычной выдачей и содержит сгенерированный ответ. В нем может быть ссылка на сайт, но чаще всего — фрагмент текста с припиской «источник». Такой формат работает по гибридной логике: сначала идет генерация, потом — поиск подтверждения. Поэтому попасть туда можно, если сайт часто цитируют, если он технически чистый и если контент дает конкретные ответы. Пока это не массовый источник трафика, но уже заметный, особенно в англоязычной выдаче.
Еще одна точка роста — Perplexity и Phind. Эти ассистенты с самого начала настроены на то, чтобы показывать, откуда они берут информацию. Ссылки встроены прямо в ответ, а не спрятаны под кнопками. Они не просто подтверждают, а строят ответ на основе нескольких сайтов сразу. Отсюда важный вывод: здесь уже работает «плотность присутствия» — если сайт упоминается в разных местах, у него больше шансов попасть в итоговую сборку. Отдельный плюс: трафик приходит сразу, а не через фильтры и поведенческие факторы.

Похожим образом работает Brave Search: он дает краткую выжимку поверх поисковой выдачи и показывает ссылки. Алгоритмы там устроены проще, но суть та же: важно быть понятным, структурированным и не казаться единственным источником истины. Чем больше у темы вариаций, тем выше шанс, что именно ваша формулировка попадет в итоговый синтез.
Классические ассистенты — ChatGPT без Browse или Gemini — пока не ориентированы на привлечение трафика. Даже если в ответе упоминается сайт, ссылка показывается не всегда, а пользователи чаще всего читают готовый текст. Оценок трафика от таких форматов пока нет, но они могут влиять на то, какие формулировки и бренды остаются в инфополе.
В нейровыдаче важны три вещи: заметность, цитируемость и техническая удобочитаемость. Контент, написанный ясно, логично и по делу, на сайтах с понятной структурой, все чаще оказывается в тех зонах выдачи, где пользователи получают ответы от нейросетей напрямую.
Упрощаем работу ИИ-моделей с вашим контентом
Собираем техническую основу и структуру текста, чтобы фрагменты легко попадали в нейровыдачу.
Читайте лучшие материалы первыми
Подписавшись на рассылку, вы соглашаетесь с Политикой Конфиденциальности.

